本筆記中使用的程式語言為python,課程為:机器学习 A-Z (Machine Learning A-Z in Chinese)
程式編輯器:spyder
python版本:3.6
如何安裝及使用packege內的程式
EX1:
import Numpy #導入程式庫
X1, X2 = Numpy .meshgrid.....
EX2:
import Numpy as np
X1, X2 = np .meshgrid..... #之後使用就可以簡化
EX3:
from sklearn.ensemble import RandomForestClassifier as RFC #直接導入sklean model 內RandomForestClassifier
classifier = RFC(......
NumPy 多維數列與矩陣運算用,最常搭配matplotlib使用
np.arange(start = X_set[:, 0].min() – 1, stop = X_set[:, 0].max() + 1, step = 0.01)
Matplotlib.pyplot 視覺化套件,只有一張圖的話使用全域 pyplot 很方便
plt.xlim(X1.min(), X1.max())
plt.scatter()plt.title(“)plt.xlabel(“)plt.ylabel(“)plt.show
pandas 數據分析用
pd.read_csv(‘XXX.xsv’)
os 文件和目錄操作,學習中主要用在自動跳到工作路徑用,避免多次手動安裝路徑
os.chdir(“D:\Machine Learning A-Z Chinese Template Folder\Part 3 – Classification\Section 10 – Logistic Regression")
random
random.betavariante( thida1, 1-thida1)
sklearn 為scikit-learn縮寫,數據處理相關模組,常用程式庫如下:
from sklearn.impute import SimpleImputer #遺失數據處理
imputer = SimpleImputer(missing_values =np.nan, strategy= ‘mean’)
imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
from sklearn.model_selection import train_test_split #自動將數據及分為訓練集及測試集
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size = 0.25, random_state = 0 )
from sklearn.preprocessing import StandardScaler #將數據標準化
sc = StandardScaler()
X_train = sc.fit_transform(X_train) #fit 會找出平均值與標準差並標準化
X_test = sc.transform(X_test) #沒有fit 會直接用上面有fit過得到的平均值與標準差進行標準化
from sklearn.preprocessing import LabelEncoder, OneHotEncoder #將文字分類轉變為數字
from sklearn.linear_model import LinearRegression #線性回歸
from sklearn.preprocessing import PolynomialFeatures #多項式回歸
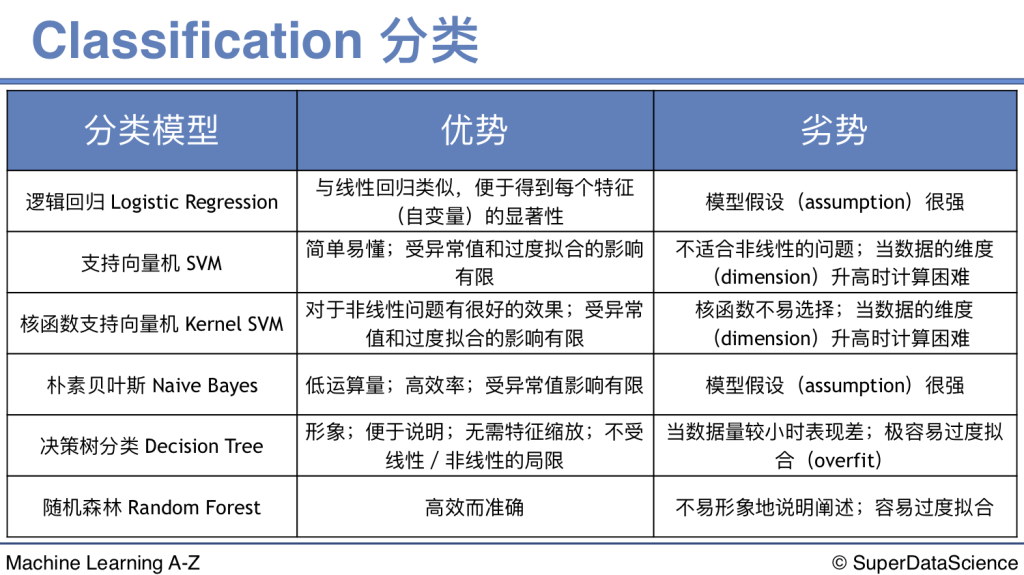
from sklearn.linear_model import LogisticRegression #邏輯回歸
classifier = LogisticRegression(random_state = 0)
classifier.fit(X_train, Y_train)
Y_pred = classifier.predict(X_test)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier as rfc
import sklearn.cluster as cl
kmeans = cl.KMeans(n_clusters = i , max_i…..
import apyori as ap
rules = ap.apriori(transations, min_support = 0.003, min_confidence = 0.2, min_lift = 3, min_length = 2)
import re #幫助清理語言資料